

The New Reality for GCCs: From Pilots to Production AI
GCCs are being asked to move beyond proof-of-concepts and deliver production-grade AI, governed, secure, and scaled across business lines. Recent industry research shows only a small minority of GCCs have reached advanced AI maturity, yet the clear differentiator for leaders is deeper AI adoption across workflows and strong platform choices that compress time-to-value. GCCs in India are rapidly becoming enterprise AI hubs, with AI roles exceeding 126,000 and the Bengaluru–Hyderabad–Chennai corridor forming the core talent triangle powering large-scale LLM initiatives. [bcg.com] [gcc.economictimes.com]
“Personal AI Supercomputers” for Teams: GB10-Powered Workstations
While rack-mounted systems tackle training at scale, GCCs also need developer-friendly systems for data preparation, RAG pipelines, fine-tuning, synthetic data generation, and L4/L5 inference experiments, ideally without booking datacenter time.
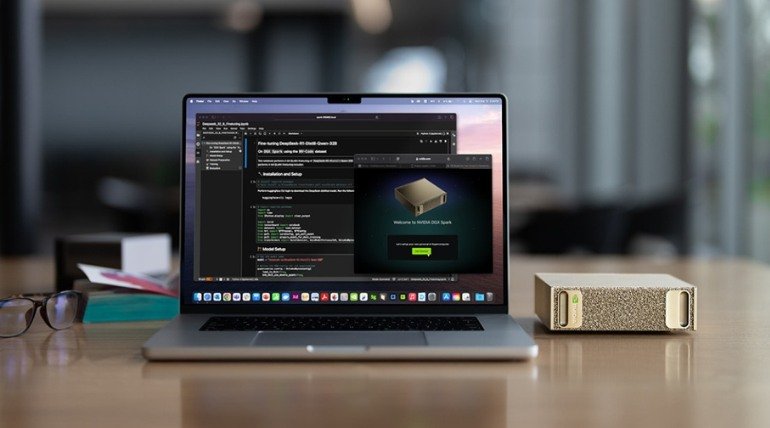
Source: NVIDIA
Introducing GB10-Based Solutions
The NVIDIA DGX Spark (formerly “Project Digits”), powered by the GB10 Grace-Blackwell Superchip, offers:
● Up to ~1 PFLOP (FP4) of AI compute
● 128 GB of unified memory for local work with models up to ~200B parameters
● ConnectX networking to cluster two units for even larger contexts [nvidia.com]
The system ships with the NVIDIA AI software stack (CUDA-X libraries, NIM microservices, DGX OS), enabling developers to prototype and fine-tune on the device, then promote to the cluster with minimal changes.
Independent reviews highlight the Spark’s role as a capable, Linux-first, CUDA ecosystem development platform. [tomshardware.com]
OEM Alternatives
OEMs, including Dell Pro Max (GB10) and HP ZGX Nano AI Station G1n, are launching their own GB10 desktop systems with the DGX stack for deskside AI development. [dell.com] [techradar.com]
Why GB10 Workstations Deliver Better TCO for Dev/Test vs. Scheduling Full HPC Nodes
For iterative fine-tuning, prompt engineering, evaluation harnesses, agent simulations, and data curation, GB10 systems offer several advantages:
Reduced queueing delays – No waiting for datacenter resources
Lower datacenter overhead – Avoid facility costs for small-scale work
Faster iteration – Teams can fail fast locally
CUDA compatibility – Seamless transition to DGX racks when ready
You retain CUDA, TensorRT-LLM, and NVLink-C2C advantages, so when a job is production-ready, it scales to DGX racks with minimal rework. This developer productivity advantage translates directly into lower cost per feature and faster time-to-value, especially when paired with a central DGX cluster for large-scale runs. NVIDIA positions Spark precisely for this “develop here, scale there” workflow. [nvidia.com]
Rule of Thumb
Use GB10 for: Local data wrangling, adapter-based fine-tuning, and evaluation loops
Reserve NVL72/8-GPU DGX for: Large-batch pretraining/RI or production-grade, ultra-low-latency inference [nvidia.com] [boston-it.com]
A Compact Primer: GB10 Workstation Features at a Glance
Compute: NVIDIA GB10 Grace-Blackwell Superchip (CPU+GPU on one module) delivering up to ~1 PFLOP FP4 for AI tasks
Memory: 128 GB unified memory, critical for big-context LLM work at the desk; cluster two units over ConnectX to raise parameter ceilings further
Software: Ships with the NVIDIA AI stack (CUDA-X, NIM, DGX OS), enabling a frictionless path from local prototype to DGX production [nvidia.com]
Compared to booking time on HPC/GPU farm nodes for early development, GB10 units can lower TCO through:
1. Far less orchestration overhead for small, iterative jobs
2. Higher developer utilization
3. Reduced datacenter energy/cooling for work that doesn’t need 8–72 GPUs yet [nvidia.com]
Why Partner with Conquer Technologies LLP for “AI Supercomputers in Compact Form Factors”
Conquer Technologies LLP partners with leading OEMs to bring you end-to-end AI infrastructure, from deskside GB10 workstations and RTX PRO Blackwell developer rigs to rack-scale DGX GB200 NVL72 deployments, so GCCs and enterprises can move from first experiment to factory-scale quickly and safely.
Strategy & Workload Mapping
We benchmark your use cases (RAG, fine-tuning, MoE, vision, agentic pipelines) against platform choices (GB10, DGX B200, NVL72) to balance performance, TCO, and energy. [boston-it.com] [aspsys.com]
Reference Architectures & Sizing
We deliver NVIDIA-validated designs, from 8-GPU nodes to NVL72 racks, with the right networking (InfiniBand/Spectrum-X), storage tiers, and cooling (air/liquid). [boston-it.com] [hpe.com]
Facility Readiness & Deployment
Power and cooling audits, manifold/CDU planning, and rapid bring-up (shortening deployment from months to weeks). [docs.nvidia.com]
Software Stack & MLOps
Rollout of NVIDIA AI Enterprise, Base Command, and Run:ai for orchestration, with governance patterns for multi-tenant GCCs. [lenovopress.lenovo.com] [boston-it.com]
FinOps & SustainOps
We model cost per token and energy curves for GB10 vs. DGX nodes vs. NVL72, helping you hit ROI and sustainability goals (liquid cooling often improves energy efficiency materially). [supermicro.com]
Lifecycle & Uptime
Integrated monitoring, failover, and predictive maintenance aligned with DGX SuperPOD constant-uptime practices. [boston-it.com]
Outcome
GCCs, hospitals, banks, and manufacturers get a compact yet industrial-strength AI platform, deployable in standard racks or labs, that accelerates time-to-first model and time-to-production, with a clear path from a GB10 desk to a DGX rack as needs grow. [nvidia.com] [boston-it.com]

")




